Running DeepSeek-R1 on a commodity laptop with vLLM
Date: 2026-02-14
vLLM is a model serving runtime supporting the most popular families of large language models (LLMs) such as DeepSeek and Llama. It exposes an OpenAI-compatible server implementing common OpenAI REST API endpoints such as the Chat, Completions and Responses API for text generation and inference, allowing existing clients and tools leveraging the OpenAI API to be reused simply by customizing the server URL. One of the main innovations of vLLM at the time it was initially released to the public is its paged attention mechanism addressing the critical bottleneck of key-value (KV) cache memory through its non-contiguous cache implementation, enabling significant efficiency and throughput gains in tasks such as text generation and inference.
vLLM is an incubation project under LF AI & Data since October 2024 ensuring vendor-neutral governance.
Follow me as I deploy my first locally hosted distilled variant of the DeepSeek-R1 model on a commodity Redmi Book 14 2024 laptop with vLLM in this exploratory lab. DeepSeek-R1 is a series of models trained via reinforcement learning available on Hugging Face.
Hardware specifications and limitations
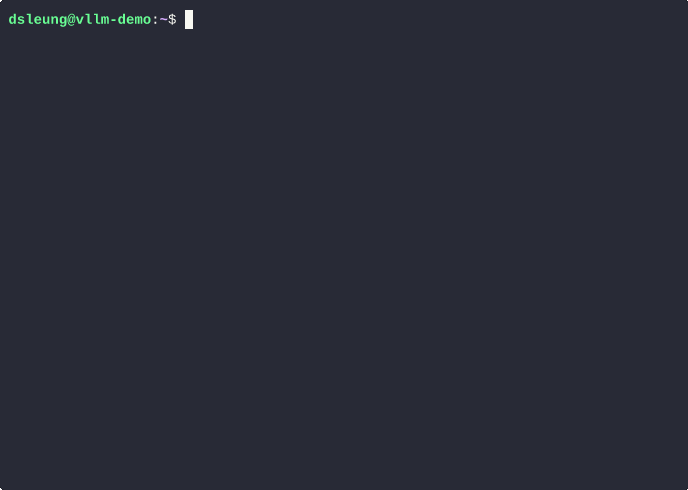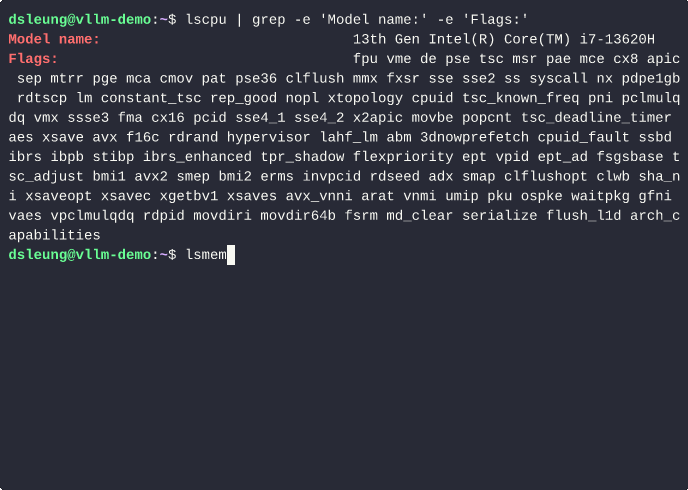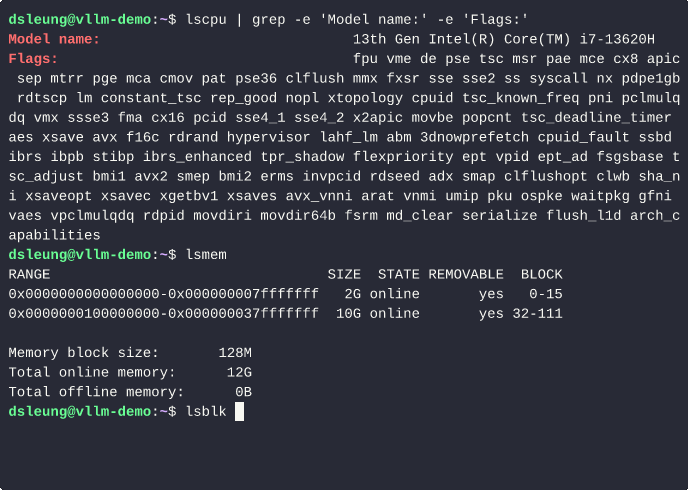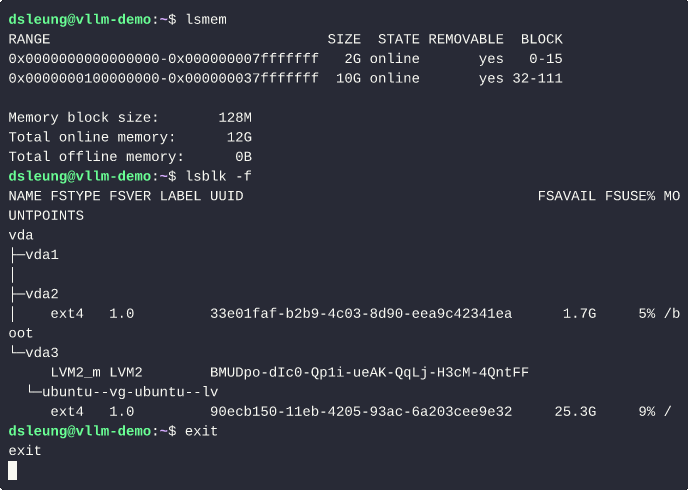
The Redmi Book 14 2024 features a 13th Gen Intel Core i7 processor with 16 CPU cores and 16 GiB of system memory. Furthermore, to isolate the lab from my laptop environment, I performed the steps described in this article in an Ubuntu 24.04 (Noble) VM with 6 vCPU cores, 12 GiB of system memory and 32 GiB for the OS disk, using CPU host passthrough to expose the laptop’s native CPU capabilities directly to the underlying VM.
Unfortunately, my CPU does not support the AVX-512 vector extensions required by the pre-compiled vLLM CPU Python wheel and Docker images so compiling and building a custom vLLM image from source is the only option.
View on Asciinema
Setting up the environment
The following packages were installed and the administrative user added to the
docker Unix group to allow running docker commands directly without sudo.
docker.io: Docker engine and container runtimedocker-buildx: the modern, default BuildKit build system for Docker images
Compiling and building a custom image with AVX-512 disabled
Reference: CPU - vLLM
Clone the vLLM GitHub repository and
make it your working directory. I used the v0.15.1 tag which is the latest
stable release at the time of writing.
git clone -b v0.15.1 https://github.com/vllm-project/vllm.git
pushd vllm/
Use the provided docker/Dockerfile.cpu Dockerfile and the vllm-openai build
target to build the Docker image. The following build arguments were specified.
VLLM_CPU_DISABLE_AVX512=true: disable AVX-512 vector extensionsmax_jobs=6: reduce the # of concurrent jobs to6(default:32) to prevent running out of memory and being OOM killed
# Specify your image repository, namespace, name and tag
# Feel free to change these values
IMAGE_REPOSITORY='quay.io'
IMAGE_NAMESPACE='donaldsebleung'
IMAGE_NAME='vllm-cpu-release-repo'
IMAGE_TAG='20260214-disable-avx512'
export IMAGE="$IMAGE_REPOSITORY/$IMAGE_NAMESPACE/$IMAGE_NAME:$IMAGE_TAG"
# Build our custom vLLM CPU image with AVX-512 disabled
docker build -f docker/Dockerfile.cpu \
--build-arg VLLM_CPU_DISABLE_AVX512=true \
--build-arg max_jobs=6 \
--target vllm-openai \
-t "$IMAGE" \
.
Push it to your image registry (optional).
docker push "$IMAGE"
Return to your home directory.
popd
View on Asciinema
Serving DeepSeek-R1 with our custom image
Reference: vllm serve - vLLM
By default, our custom image runs vllm serve $ARGS where $ARGS is the
command-line arguments passed to docker run. Verify this with
docker inspect.
docker inspect "$IMAGE" | \
jq --raw-output '.[0].Config.Entrypoint | join(" ")'
Sample output:
vllm serve
Let’s deploy the
deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
model from Hugging Face with vLLM. It is a model distilled from DeepSeek-R1
based on Qwen with just 1.5 billion (B) parameters, which should run at a
reasonable speed on our Intel CPU without GPU / NPU acceleration for
demonstration purposes only.
The vLLM command looks like this.
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B \
--dtype=bfloat16 \
--api-key=my-very-secure-api-key
Here’s how it translates to docker run.
# Set an API key for authentication
# Feel free to change these values
export OPENAI_API_KEY="my-very-secure-api-key"
# Serve the model with our custom image
docker run --rm \
--name vllm-openai \
-d \
-p 8000:8000 \
--security-opt seccomp=unconfined \
--cap-add SYS_NICE \
--shm-size=4g \
-e VLLM_CPU_KVCACHE_SPACE=4 \
"$IMAGE" \
deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B \
--dtype=bfloat16 \
--api-key="$OPENAI_API_KEY"
Here’s a breakdown of the key options used.
--security-opt seccomp=unconfined: disable the default Seccomp confinement for containers to allow NUMA-related syscalls such asmigrate_pages. Not ideal from a security perspective but sufficient for demo purposes--cap-add SYS_NICE: add theSYS_NICEcapability to the container recommended by vLLM for improved performance--shm-size=4g: size of/dev/shmin GiB-e VLLM_CPU_KVCACHE_SPACE=4: set the KV cache size to4Giexplicitly (the default)--dtype=bfloat16: passed tovllm serveto improve accuracy and performance--api-key: specifies the OpenAI API key to authenticate inference requests
Wait a few minutes for vLLM to boot and load our model. Optionally follow the
logs with docker logs -f vllm-openai.
i=0
docker logs vllm-openai 2>&1 | \
grep "Application startup complete." > /dev/null
while [ "$?" -ne 0 ]; do
echo "Waiting $i seconds for vLLM to become ready ..."
i=$((i + 1))
sleep 1
docker logs vllm-openai 2>&1 | \
grep "Application startup complete." > /dev/null
done
echo "vLLM is ready after $i seconds."
Let’s explore the most common vLLM API endpoints. It’s mostly compatible with the OpenAI API with few differences.
View on Asciinema

Exploring vLLM common API endpoints
Reference: Logging Configuration - vLLM
GET /health: health checks
The GET /health endpoint checks whether vLLM is up and running.
curl -is http://localhost:8000/health
Sample output:
HTTP/1.1 200 OK
date: Sat, 14 Feb 2026 09:10:57 GMT
server: uvicorn
content-length: 0
GET /metrics: Prometheus metrics
The GET /metrics endpoint exposes vLLM-related metrics in
Prometheus format. Configure your monitoring stack to
scrape this endpoint for monitoring, alerts and visualization.
curl -is http://localhost:8000/metrics | head
Sample output:
HTTP/1.1 200 OK
date: Sat, 14 Feb 2026 09:22:18 GMT
server: uvicorn
content-length: 55977
content-type: text/plain; version=1.0.0; charset=utf-8
# HELP python_gc_objects_collected_total Objects collected during gc
# TYPE python_gc_objects_collected_total counter
python_gc_objects_collected_total{generation="0"} 12629.0
python_gc_objects_collected_total{generation="1"} 1879.0
GET /load: server load metrics
The GET /load endpoint reports the server load on the vLLM instance.
curl -s http://localhost:8000/load | jq
Sample output:
{
"server_load": 0
}
GET /v1/models: list available models
The GET /v1/models endpoint is OpenAI-compatible and lists the available
models for inference.
This endpoint requires bearer authentication with the
Authorization
header if --api-key / VLLM_API_KEY is specified with vllm serve.
curl -s -H "Authorization: Bearer $OPENAI_API_KEY" \
http://localhost:8000/v1/models | jq
Sample output:
{
"object": "list",
"data": [
{
"id": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"object": "model",
"created": 1771062179,
"owned_by": "vllm",
"root": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"parent": null,
"max_model_len": 131072,
"permission": [
{
"id": "modelperm-97eb0d294b2de221",
"object": "model_permission",
"created": 1771062179,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
}
]
}
Completions API: send a prompt to vLLM for inference
The Completions API is part of the OpenAI API specification. It is fully supported by vLLM.
Let’s send an inference request to vLLM using the Completions API in the next section and watch DeepSeek-R1 respond to our prompt in real time!
View in Asciinema

Sending an inference request to vLLM and seeing it all in action
Reference: OpenAI-Compatible Server - vLLM
Let’s ask DeepSeek-R1 to introduce itself in 100-150 words.
Explain DeepSeek-R1 to a non-technical audience in 100-150 words.
The Completions API exposes the endpoint POST /v1/chat/completions which
accepts a JSON payload containing the following fields.
model: the ID of the model returned inGET /v1/modelsmessages: a list of messages inrole/contentformat with thecontentkey containing the actual prompt.rolecan be eithersystemoruserfor system and user prompts, respectivelymax_tokens: specifies the maximum number of tokens the model should returntemperature: a tunable parameter to optimize the response from the model. DeepSeek-R1 recommends setting it between0.5and0.7, with0.6being the optimal temperature
Let’s prepare a request.json with our request payload.
{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"messages": [
{
"role": "user",
"content": "Explain DeepSeek-R1 to a non-technical audience in 100-150 words."
}
],
"max_tokens": 1024,
"temperature": 0.6
}
Send the inference request and wait for the response. Since we’re running on an Intel CPU processor directly with no GPU / NPU acceleration, wait a minute or two for the model to respond to our prompt.
Save the response in a separate file response.json.
curl -s -XPOST \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d "$(cat request.json)" \
http://localhost:8000/v1/chat/completions \
> response.json
Let’s extract the raw text from the response payload. Take the last line as the
previous lines ending with </think> are part of DeepSeek-R1’s reasoning flow.
cat response.json | \
jq --raw-output '.choices[0].message.content' | \
tail -1
Sample output, formatted as a quote below for clarity.
DeepSeek-R1 is an advanced AI developed by DeepSeek, known for its powerful capabilities in solving complex problems. It excels at handling technical queries, answering questions, and solving math problems with accuracy. Unlike traditional tools, DeepSeek-R1 not only provides answers but also explains the reasoning behind them, offering a deeper understanding. Its versatility extends beyond mathematics, capable of answering general knowledge, solving technical issues, and providing creative insights. The user-friendly interface makes it accessible to a broad audience, from students to professionals. DeepSeek-R1 is reliable, giving consistent, accurate answers, making it a trusted ally for problem-solving.
Not bad! DeepSeek-R1 was able to satisfy our request and give a short, succint overview of itself in natural language.
View on Asciinema

Concluding remarks and going further
This article covers only the tip of the iceberg in terms of local model serving with vLLM. Some interesting next steps would be to:
- Connect your locally hosted model with an MCP server to power your agentic workflows
- Connect it with OpenClaw hosted locally on the same or a different server to boost your software development workflow with ChatOps
- Deploy and serve your model on Kubernetes with a tried and tested model serving platform such as KServe
I hope you enjoyed this article as much as I did writing it and stay tuned for updates ;-)
Subscribe:
![]()
![]()
![[Valid RSS]](/assets/images/valid-rss-rogers.png)
![[Valid Atom 1.0]](/assets/images/valid-atom.png)